Google представила новую функцию для своей модели ИИ Gemini 2.5, которая позволяет выделять и анализировать части изображений с помощью обычных текстовых запросов. Теперь пользователи могут обращаться к модели на естественном языке и получать ответ, который учитывает сложные запросы, например «человек с зонтом» или «все, кто не сидит». Gemini распознает не только четкие объекты, но и абстрактные понятия, такие как «беспорядок» или «повреждение», а также может находить элементы по тексту на изображении.
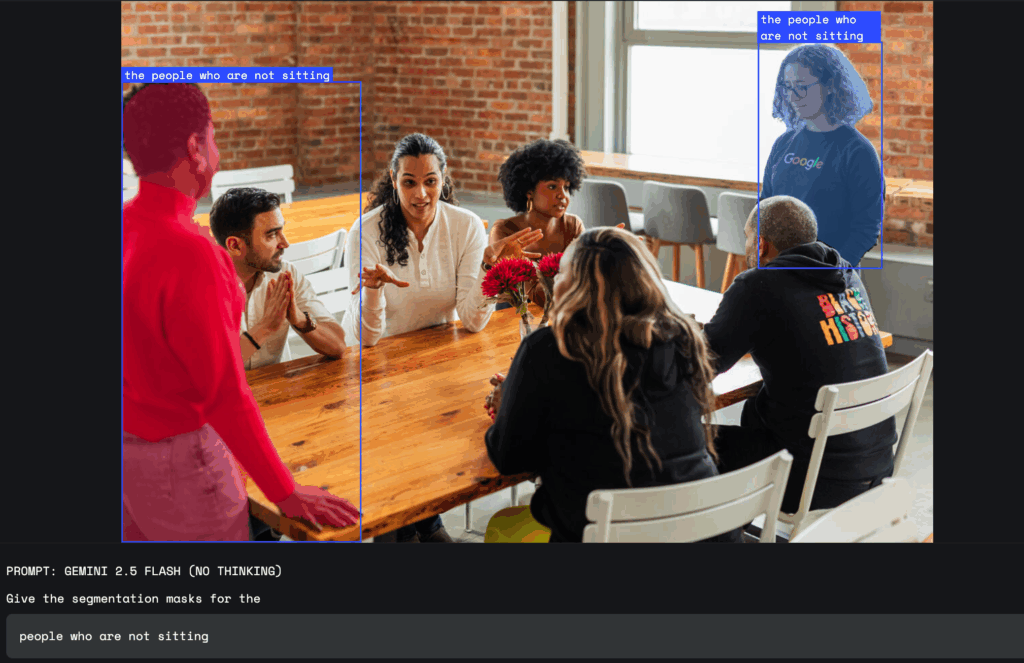
Функция поддерживает многоязычные запросы и может давать подписи к объектам на других языках. Пользователи получают результат в виде координат выбранной области, маски пикселей и подписи, что позволяет быстро определить нужную часть изображения. Для этого не нужно использовать отдельные инструменты или модели, так как все обрабатывает сама модель Gemini.
Разработчики имеют доступ к новой возможности через Gemini API. Google рекомендует для наилучшей работы использовать модель «gemini-2.5-flash» и установить параметр «thinkingBudget» на ноль для мгновенного ответа. Первые испытания можно проводить в Google AI Studio или через Python Colab.
Функция станет полезной дизайнерам, которые теперь могут выделять детали на фото простыми командами, например «выделить тень здания». В сфере безопасности труда Gemini поможет находить нарушения, например «все люди на строительной площадке без шлема». В страховании эта возможность позволяет автоматически отмечать поврежденные здания на аэрофотоснимках, что экономит время при оценке убытков.

