Alibaba представила Qwen-Image — новую ИИ-модель с 20 миллиардами параметров, которая создает изображения с высококачественным текстом в разнообразных стилях. Разработчики отмечают , что Qwen-Image поддерживает двуязычный текст и легко переключается между языками, а также генерирует текст в различных визуальных контекстах — от уличных сцен до слайдов презентаций.
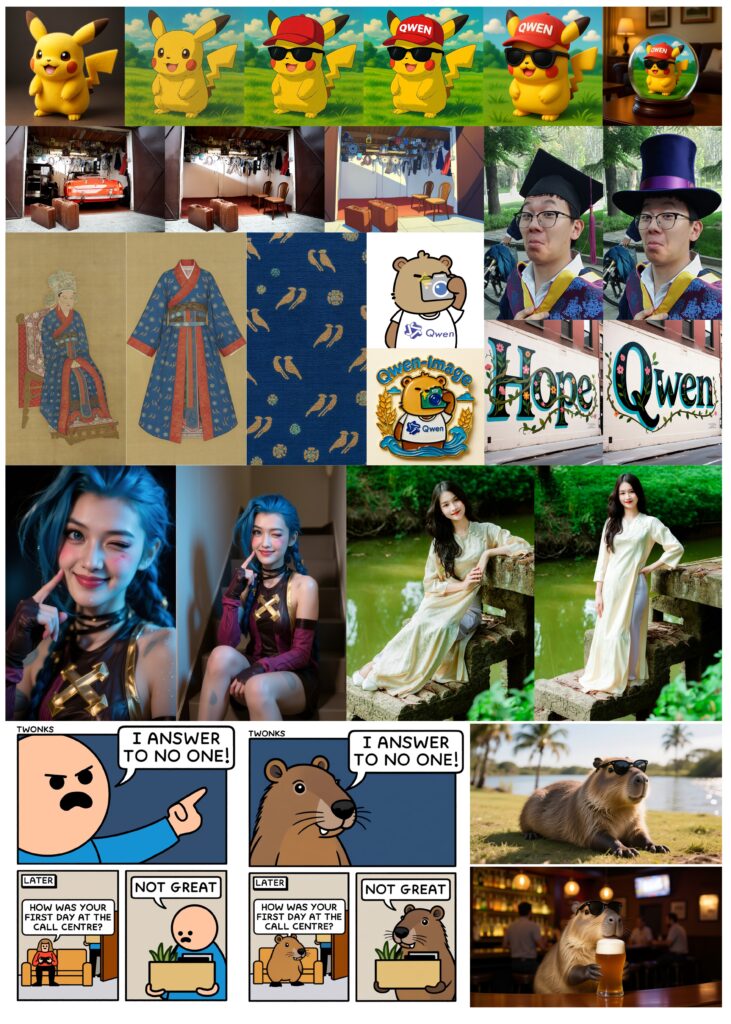
Модель позволяет не только создавать новые изображения, но и редактировать их — изменять стиль, добавлять или удалять объекты, а также корректировать позы людей на фото. Qwen-Image выполняет задачи классического компьютерного зрения, например, оценивает глубину изображения или создает новые ракурсы, сохраняя оригинальное содержание.
Архитектура Qwen-Image включает три основных компонента: Qwen2.5-VL для понимания текста и изображений, Variational AutoEncoder для сжатия изображений и Multimodal Diffusion Transformer для создания финального результата. Новая технология MSRoPE обеспечивает точное размещение текста в изображениях, что повышает качество сочетания текста и картинки даже при разных разрешениях.
Команда Alibaba построила обучающий набор данных без использования ИИ-сгенерированного контента, сосредоточившись на фотографиях природы, дизайне, изображениях людей и синтетических примерах. Дополнительные фильтры отсекают изображения низкого качества, а различные подходы к рендерингу текста обеспечивают разнообразие данных для обучения.
В тестах Qwen-Image обошла несколько коммерческих моделей, таких как GPT-Image-1 и Flux.1, особенно в создании и редактировании изображений, а также в точности рендеринга китайских символов. Модель доступна бесплатно на GitHub и Hugging Face, а пользователи могут протестировать её в живой демонстрации .

