Исследователи из Rice University, Johns Hopkins University и Nvidia представили новый подход к обучению мультимодальных ИИ, используя простые аркадные игры вместо специализированных математических наборов данных. Они разработали метод «Visual Game Learning» на основе модели Qwen2.5-VL-7B, где ИИ тренируется, играя в варианты игр Snake и Tetris.
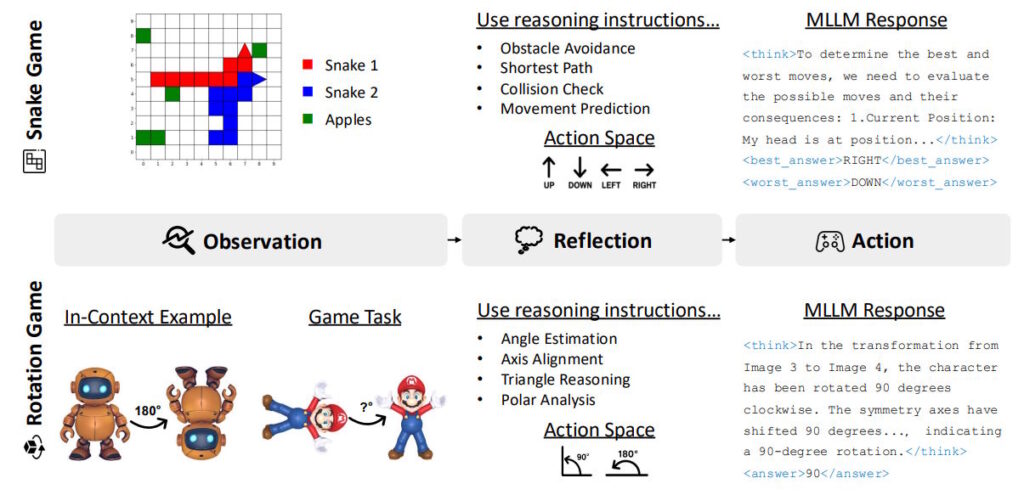
Для каждой игры исследователи создали 36 тысяч обучающих примеров с разным уровнем сложности. Тренировка на Snake улучшила способность модели решать задачи с координатами и выражениями, а обучение на игре с вращением повысило точность в определении углов и длин. При этом для 3D-объектов использовали Hunyuan3D как источник данных. После такого обучения модель лучше ориентируется в пространственных задачах и демонстрирует улучшенные навыки планирования ходов.
Результаты тестирования показали, что модель, обученная на играх, достигла точности 50,6 процента на математических бенчмарках, обогнав специализированную модель MM-Eureka-Qwen-7B, которая показала 50,1 процента. Особенно заметный прогресс был в задачах с геометрией, где показатели почти удвоились. На общих тестах ViGaL получила 53,9 процента, что выше, чем у GPT-4o, но немного уступает Gemini 2.0 Flash.
После обучения на играх модель проверили на классических Atari-играх, таких как Breakout и Ms. Pac-Man, а также на различных задачах по математике, геометрии и анализу 3D-сцен. Здесь ViGaL существенно превысила базовую версию модели по результатам. Исследователи отметили, что подсказки шаг за шагом и специальный подбор вознаграждений в процессе обучения повысили точность еще на несколько процентов.
Использование подхода с подкреплением дало прирост производительности на 12,3 процента, тогда как стандартное дообучение уменьшило точность. Увеличение объема данных также положительно повлияло на результаты. Исследователи считают, что подобные игровые среды могут стать эффективным способом обучения ИИ для развития общих навыков рассуждения.

